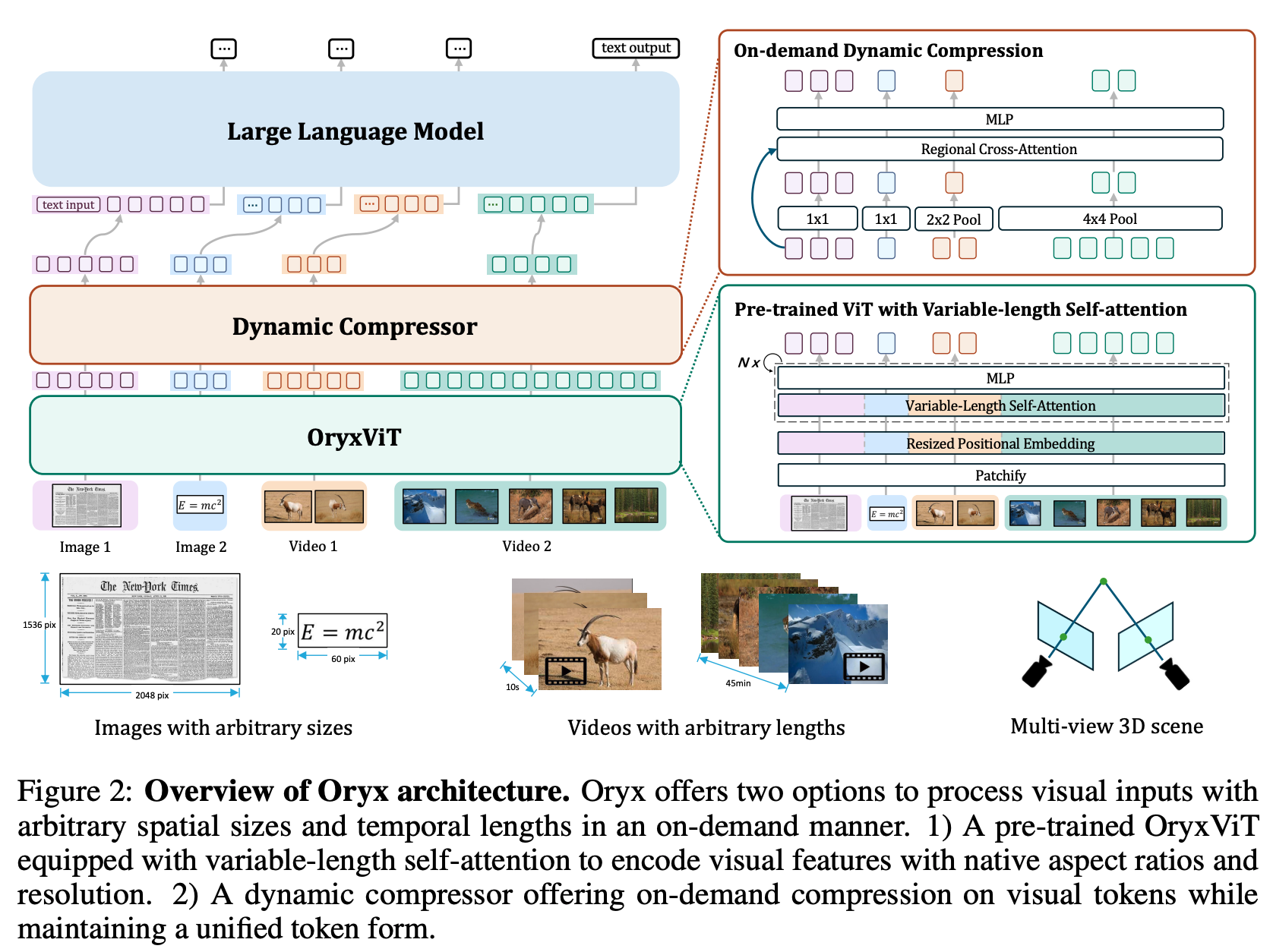
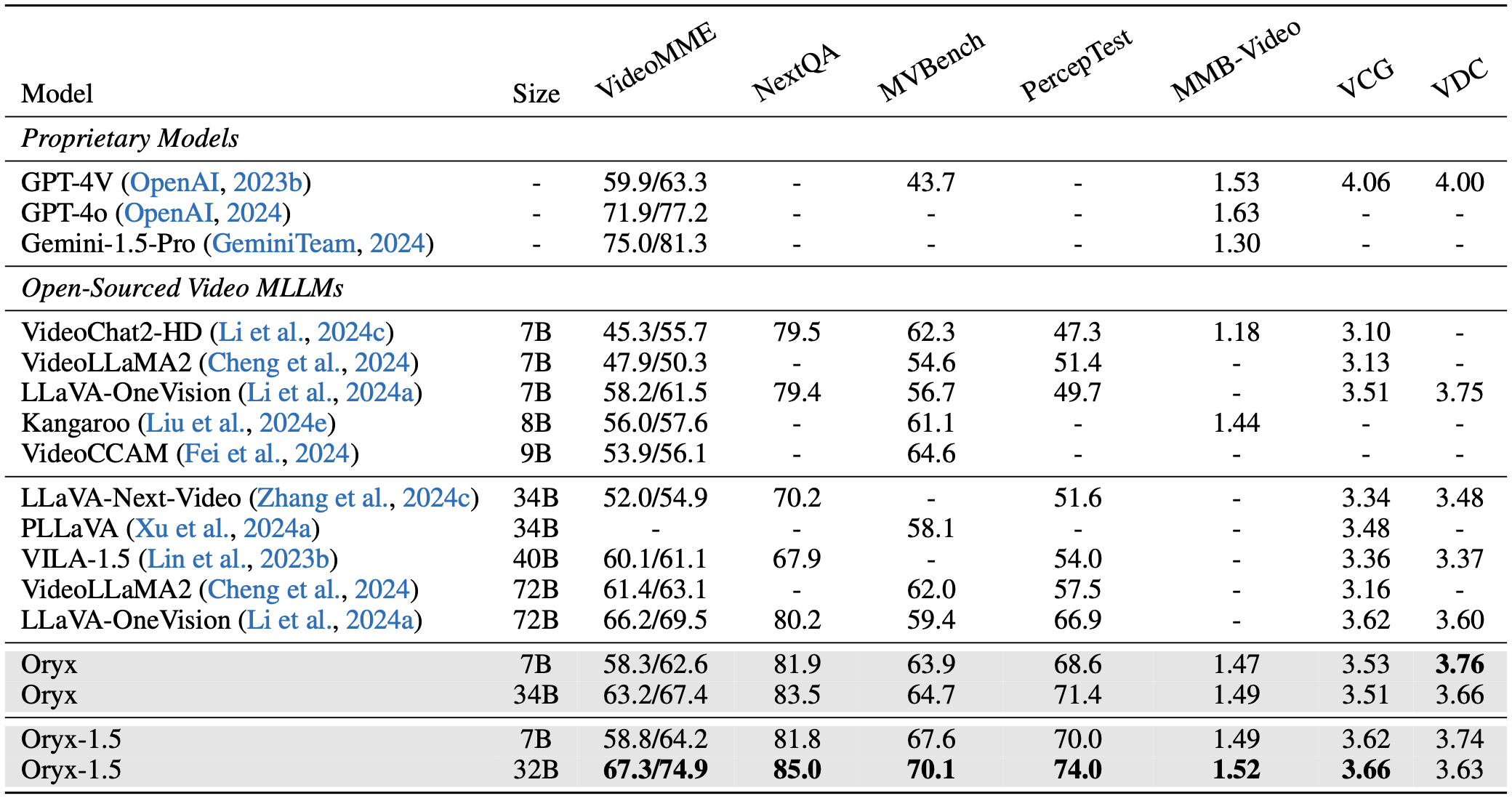
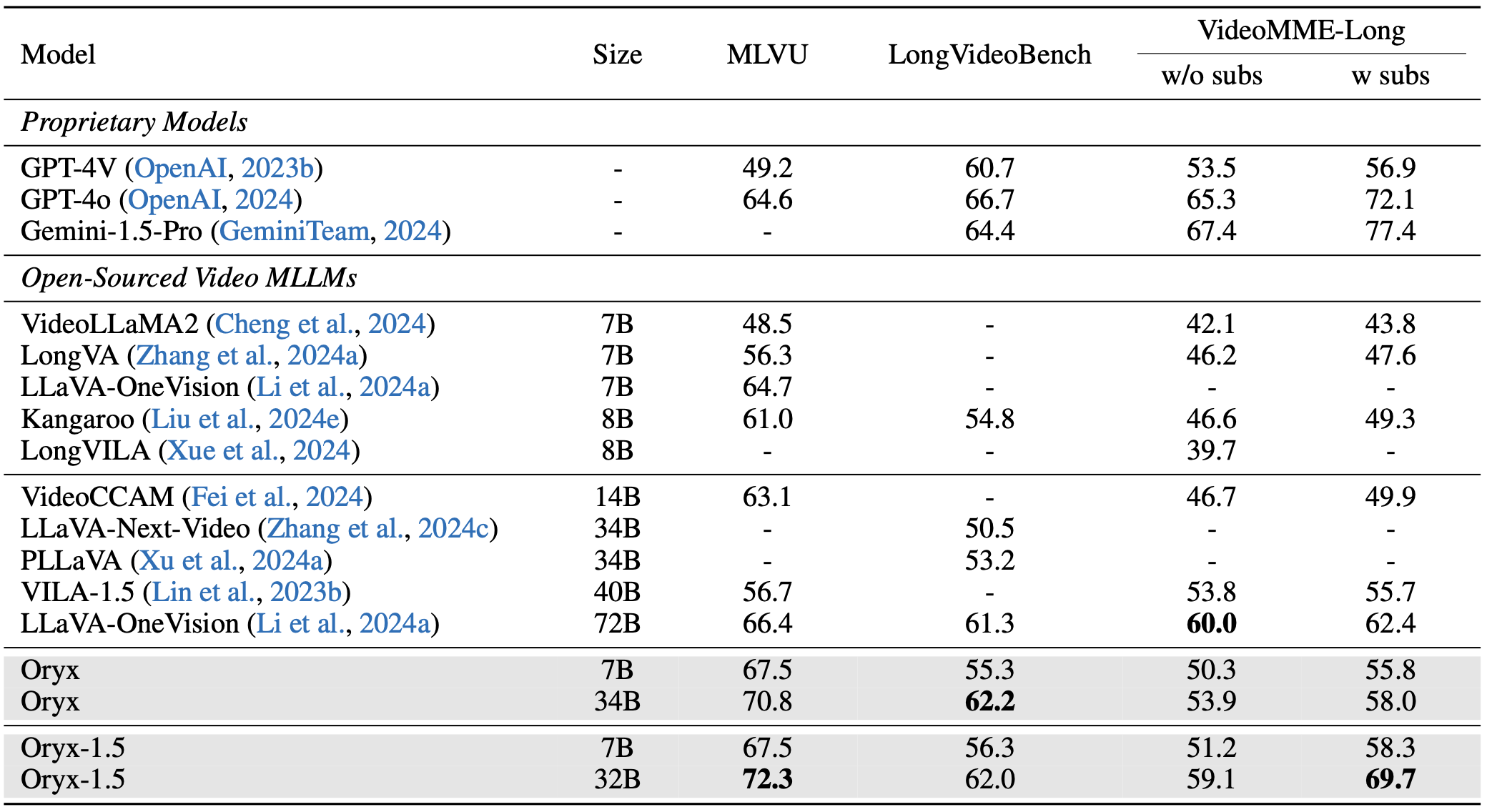
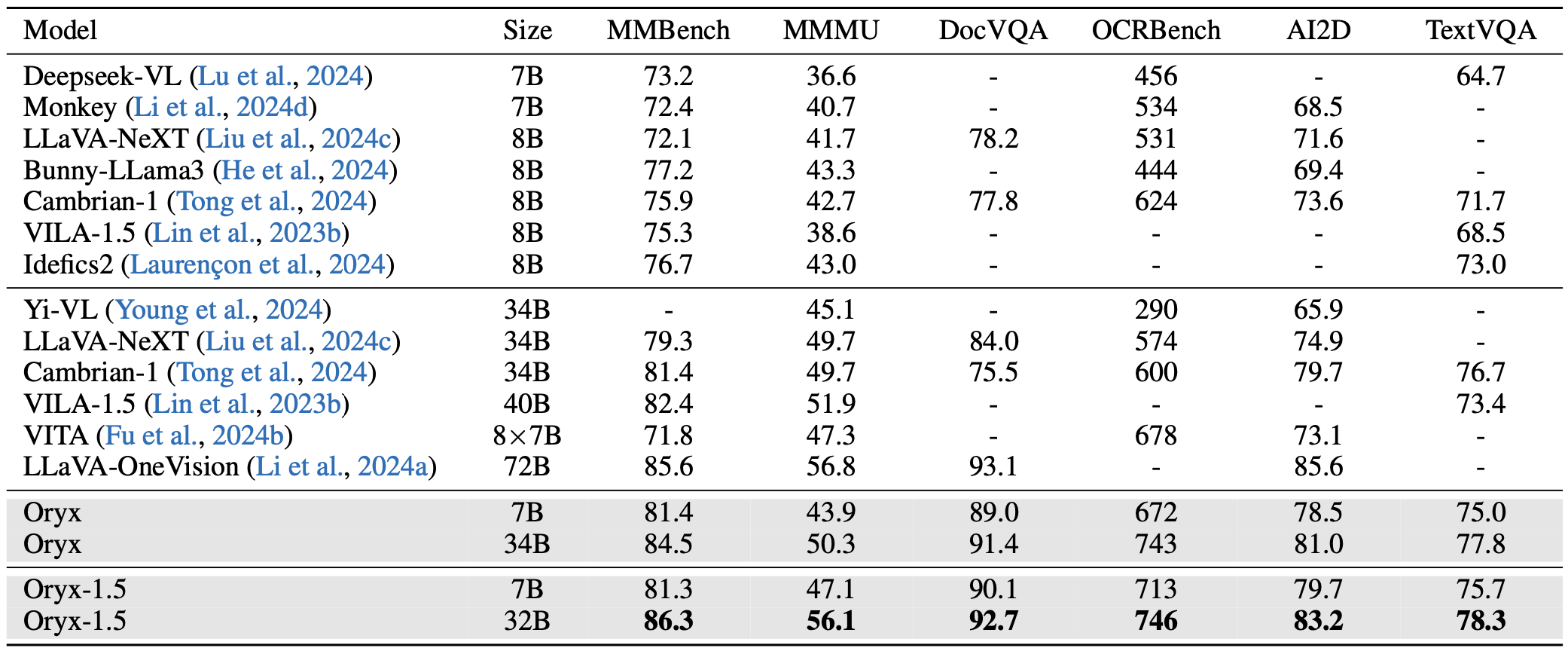
Visual data comes in various forms, ranging from small icons of just a few pixels to long videos spanning hours. Existing multi-modal LLMs usually standardize these diverse visual inputs to a fixed resolution for visual encoders and yield similar numbers of tokens for LLMs, which is non-optimal for multimodal understanding and inefficient for processing long visual content. To solve the problem, we propose the Oryx, a unified multimodal architecture for the spatial-temporal understanding of images, videos, and multi-view 3D scenes. Oryx offers an on-demand solution to seamlessly and efficiently process visual inputs with arbitrary spatial sizes and temporal lengths with two core designs: 1) a pre-trained OryxViT model that can encode images at any resolution into LLM-friendly visual representations; 2) a dynamic compressor module that supports 1x to 16x compression on visual tokens by request. Thanks to these designs, Oryx accommodates extremely long visual contexts like videos with lower resolution and high compression while maintaining high recognition precision for tasks like document understanding with native resolution and no compression. Beyond the architectural improvements, enhanced data curation and specialized training on long-context retrieval and spatial-aware data help Oryx achieve great capabilities in image, video, and 3D multimodal understanding simultaneously.




@article{liu2024oryx,
title={Oryx MLLM: On-Demand Spatial-Temporal Understanding at Arbitrary Resolution},
author={Liu, Zuyan and Dong, Yuhao and Liu, Ziwei and Hu, Winston and Lu, Jiwen and Rao, Yongming},
journal={arXiv preprint arXiv:2409.12961},
year={2024}
}